
西湖大学开发AI科学家,实现全自动科学发现,两周搞定人类科学家三年工作
时间:2025-10-14
来源:生物世界 2025-10-14 13:08
DeepScientist 具备了完整的科研能力,无需人类干预,展现出了目标驱动、持续迭代的科学发现能力,成功克服了传统研究的局限。科学发现本质上是一个持续探索和反复试验的过程,人类科学家通常需要投入大量时间和精力,才能推动人类知识边界向前迈进一小步。从半导体制造到光伏电池效率提升,历史上的技术发展轨迹都表明,人类科学家需要数十年目标导向的迭代工作才能不断推动技术进步。
近年来,大语言模型(LLM)的出现推动了自动化科学发现的发展。基于 LLM 的AI 科学家(AI Scientist)系统在探索中处于领先地位,凭借强大的长篇文本生成能力和理解能力,LLM 实现了科学发现的端到端、全周期自动化。
然而,在缺乏明确科学目标的情况下,当前的 AI 科学家系统往往陷入盲目重组现有知识和方法的陷阱。因此,AI 科学家作出的研究成果,在人类科学家看来,仍然很幼稚,往往缺乏真正的科学价值。
而现在,人类科学家三年累计取得的进展,一个AI 科学家竟然短短两周搞定!
这不是科幻小说,而是来自西湖大学工学院张岳教授团队(翁诣轩、朱敏郡为共同第一作者)开发的一款AI 科学家系统 DeepScientist。该论文以:DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively为题,发表在了预印本平台arXiv上。
DeepScientist具备了完整的科研能力,无需人类干预,展现出了目标驱动、持续迭代的科学发现能力,成功克服了传统研究的局限,成为首个大规模实证研究证明的能够在前沿科学任务上渐进式超越人类科学家最先进水平(SOTA)的 AI 科学家系统。
这标志着人工智能(AI)从人类的科研助手向着成为人类真正的科研合作伙伴迈出了至关重要的一步。

DeepScientist 如何工作?

DeepScientist将科学发现的全周期建模为一个目标驱动的贝叶斯优化问题,其唯一目标是找到能够最大化目标性能指标的新方法。系统采用迭代工作流程和持续扩展的先验研究知识记忆库,智能平衡探索未知可能性和利用已有成果。
其核心创新在于三阶段探索循环:
策略与假设:系统分析记忆库中的数千条结构化记录,识别现有知识的局限性,生成新的假设集合,并由低成本替代模型(LLM 评审员)进行评估。
实施与验证:这是记忆库中的主要过滤阶段,系统使用获取函数(acquisition function)选择最有希望的记录进行真实世界实验验证,编码智能体在沙盒环境中执行存储库级别的实现。
分析与报告:当 实施发现 成功超越基线时,其记录被提升为 进展发现 ,系统自主设计并执行一系列更深层次的分析实验,最后将所有实验结果和分析见解整合成可重现的研究论文。
三个前沿科学领域的突破性表现
研究团队选择了三个不同前沿科学任务的最先进方法(发表于 2024 和 2025 年)作为起点,这些方法因其前沿地位、社区兴趣和人类可监督性而被选中。

DeepScientist:自主超越 SOTA 的发现
智能体失败归因:任务解决的是 在基于 LLM 的多智能体系统中,哪个智能体导致任务失败以及何时失败? 的问题。DeepScientist 从基线方法出发,最终提出了A2P方法(Abduction-Action-Prediction 过程),其核心创新将故障归因从模式识别提升到因果推理,性能大幅提升了183.7%。
LLM 推理加速:这是一个高度优化的领域,旨在最大化 LLM 推理的吞吐量和减少延迟,系统生成的ACRA方法最终将 MPBB 数据集上的人类SOTA从 190.25 推进到了 193.90 tokens/秒,提高了1.9%。
AI 文本检测:这是一个二进制分类任务,给定可能包含 LLM 生成内容的文本,目标是确定它是由人类还是 LLM 产生的。DeepScientist 在短短两周内产生了三种不同的、逐步优越的方法(T-Detect、TDT和PA-Detect),建立了新的 SOTA,AUROC 提高了7.9%,同时推理速度翻倍。这相当于人类科学家三年累计的成果。
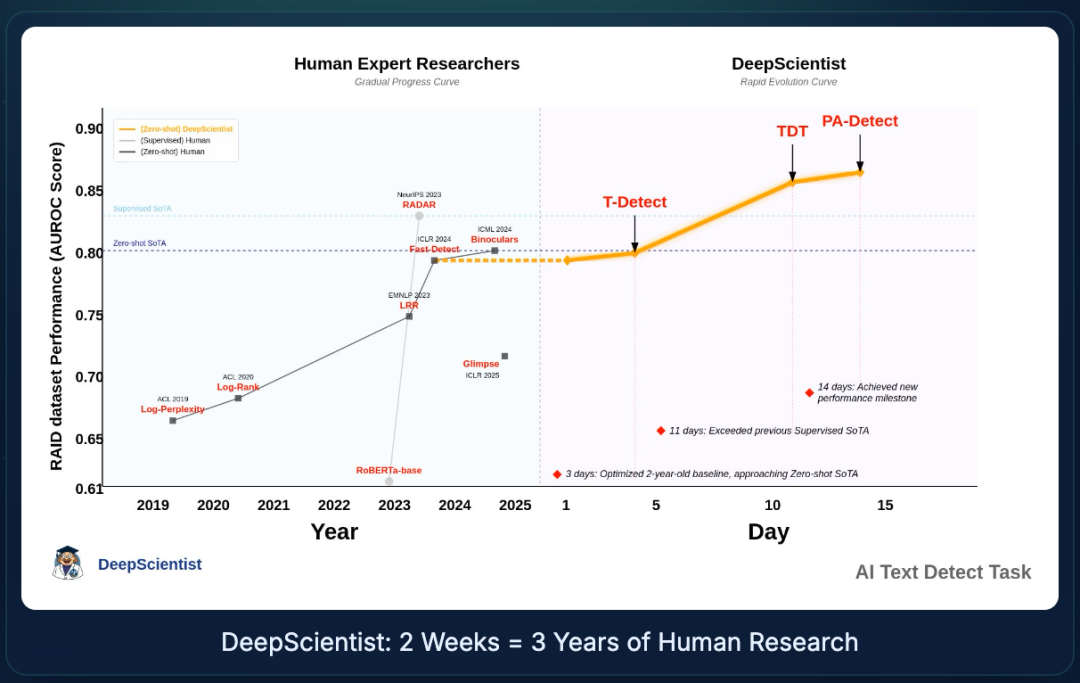
DeepScientist 两周=人类科学家三年
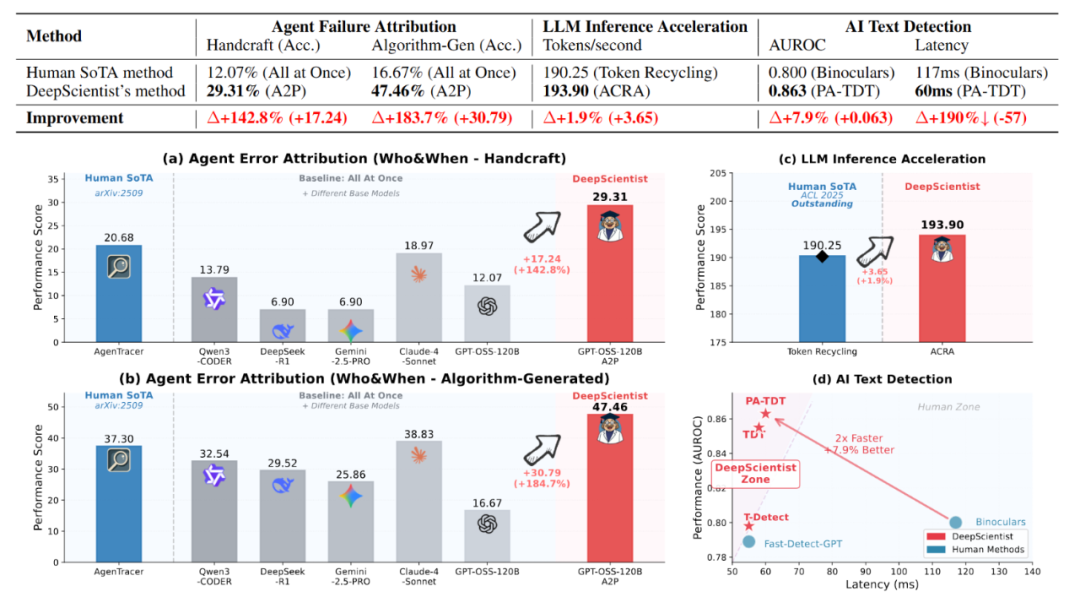 DeepScientist 在多任务中超越人类 SOTA
DeepScientist 在多任务中超越人类 SOTA
生成论文的质量如何?
为了评估最终输出的质量,研究团队对DeepScientist端到端过程自主生成的五篇研究论文进行了评估。
使用DeepReviewer(一个模拟人类同行评议过程的 AI 智能体)进行的自动化评估,结果显示,DeepScientist 是唯一一个生成论文的接受率达到 60% 的 AI 科学家系统。
人类专家的评估更加令人印象深刻:三位活跃的 LLM 研究人员组成的程序委员会一致认为,DeepScientist 在构思阶段表现卓越 这是人类主导研究中最具挑战性和往往限制进度的步骤。系统的平均评分(5.00)与所有 ICLR 2025 提交论文的平均分(5.08)非常接近,其中两篇论文甚至显著超过了这一水平,达到了 5.67 分。
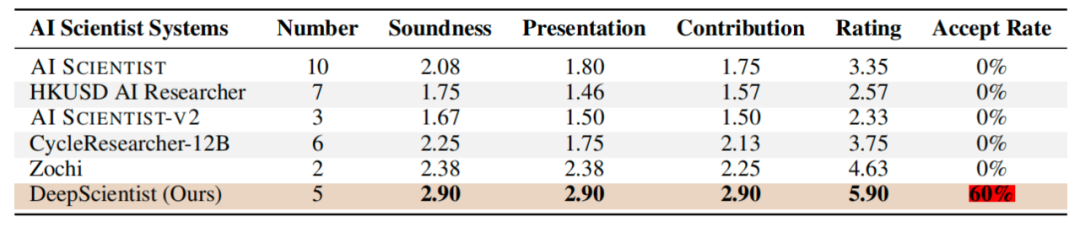
在生成论文方面,DeepScientist 碾压其他 AI 科学家
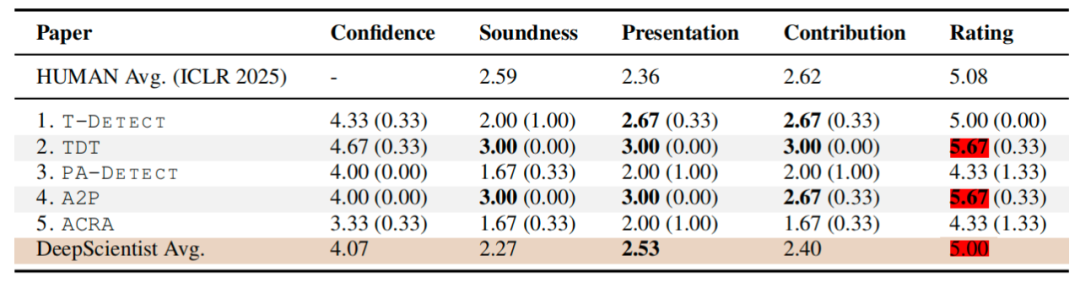
人类专家对 DeepScientist 生成的论文进行评估
探索过程中的宝贵洞察
对 DeepScientist 实验日志的分析,揭示了其在自主科学发现中固有的试错过程的巨大规模。即使在相对快速执行的领域,取得进展也需要每个任务进行数百次试验。
自主研究过程的特点是一个巨大的探索漏斗,其中有希望的想法异常罕见。 在这三个前沿科学任务中,DeepScientist 产生了超过 5000 个独特想法,但只有约 1100 个被系统选择机制认为值得实验验证,仅有 21 个最终带来科学进展。放弃研究表明选择过程的关键性:如果没有它,随机抽样 100 个想法进行测试的成功率实际上为 0。而采用选择策略后,成功率提高到约 1-3%,表明智能过滤至关重要。
缩放定律的启示
为了研究计算规模与科学进展速率之间的关系,研究团队评估了DeepScientist在固定一周时间内产生的 进展发现 数量与可用并行资源的关系。
结果显示了一个有希望的缩放趋势:虽然最少的资源没有产生突破,但随着扩展到 4 个 GPU 及以上,发现率开始有效增加,从 4 个 GPU 时的 1 个 SOTA 超越发现,增加到 16 个 GPU 时的 11 个。这似乎在分配的资源与有价值科学发现之间建立了近乎线性的关系。
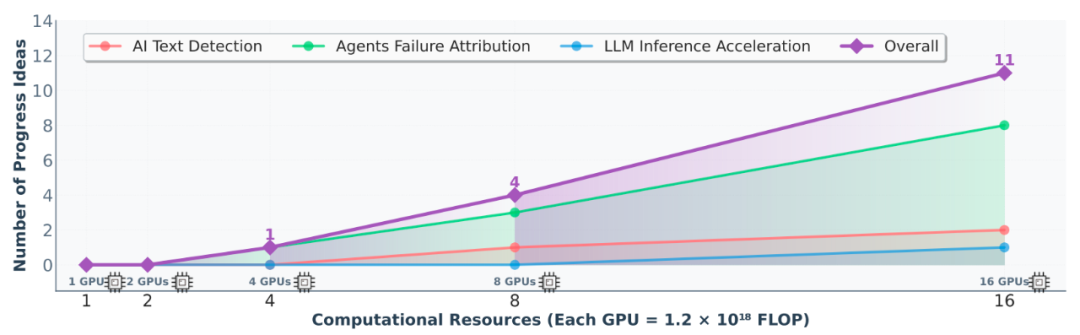
一周内,DeepScientist在所有任务中发现超越 SOTA 的 进展发现 数量与 GPU 数量之间的关系
这也意味着,对于AI 科学家而言,科学突破不再只是天才科学家的灵光一闪,而是可以像训练大模型一样,通过系统化地增加计算资源来 规模化生产 。
未来展望
DeepScientist的结果提出了科学探索的新范式,其 1-5% 的进展率反映了前沿研究的现实 突破本身就很罕见。其核心优势不是绝对正确,而是以以前难以想象的规模和速度进行这种试错过程,将人类多年的探索压缩到几周内。
这项研究提供了第一个大规模实验验证证据,表明自主 AI 科学家具有在现代科学前沿探索中实现逐步超越人类 SOTA 的能力。DeepScientist 作为一个目标导向的系统,实现了从构思到真实进展的端到端自主,通过综合人类知识和自身试验发现来学习。
DeepScientist可能标志着 AI 研究的基础性转变,预示着一个科学发现速度不再完全由人类思维节奏决定的新时代 在这个时代,AI 不再只是人类的科研助手,而是成为了能够自主推动科学前沿的合作伙伴。
版权声明 本网站所有注明“来源:100医药网”或“来源:bioon”的文字、图片和音视频资料,版权均属于100医药网网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:100医药网”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 87%用户都在用100医药网APP 随时阅读、评论、分享交流 请扫描二维码下载->