
Nature:多巴胺神经元中的未来奖励多维分布图,科学家解锁大脑的“奖励预测”密码
时间:2025-06-07
来源:100医药网 2025-06-07 11:04
这项研究不仅揭示了多巴胺神经元如何编码未来奖励的时间和数量分布,还展示了这种编码方式如何影响动物的行为。在当今快节奏的生活中,无论是人类还是动物,都需要在复杂多变的环境中做出决策,这些决策往往基于对未来奖励的预期,比如,我们可能会因为期待一顿美食而选择耐心等待,或者因为预期的回报而努力工作。那么,大脑是如何预测和评估这些未来奖励的呢?
近日,一篇发表在国际杂志Nature上题为 A multidimensional distributional map of future reward in dopamine neurons 的研究报告中,来自葡萄牙尚帕利莫未知技术研究中心等机构的科学家们通过研究揭示了多巴胺神经元在这一过程中的关键作用,为我们理解大脑的决策机制提供了新的视角。
多巴胺神经元(DANs)在大脑中扮演着重要的角色,其能通过信号传递来指导行为,传统上,这些神经元被认为主要负责传递 奖励预测误差 ,即实际奖励与预期奖励之间的差异。然而,这种简单的模型忽略了奖励的时间和数量分布等重要信息。这项研究中,研究人员提出了一种更复杂的模型 时间-数量强化学习(TMRL),其能学习未来奖励的时间和数量的联合分布。
在这项研究中,科学家们通过训练小鼠进行气味条件反射实验记录了其机体中的多巴胺神经元活动;实验中,不同的气味提示了不同时间延迟和数量的奖励,结果发现,多巴胺神经元不仅对奖励的预测误差有反应,还能编码奖励的时间和数量的分布,这种编码方式使得大脑能从短暂的神经元活动(仅450毫秒)中构建出一个关于未来奖励的二维概率图。
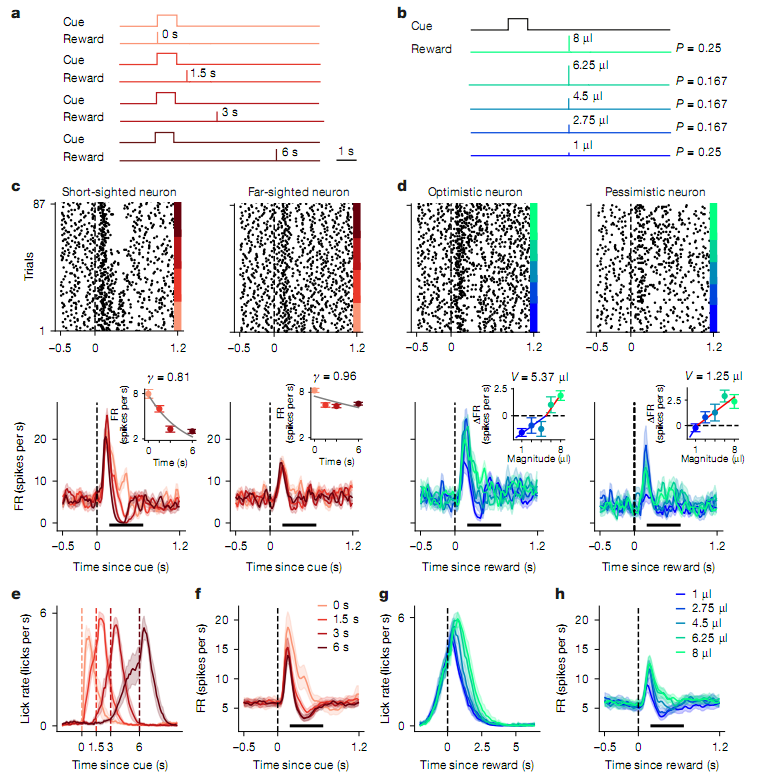
DANs是由奖励大小和时间所调节的
在人工智能领域,强化学习算法已经取得了巨大的成功,其能通过学习环境中的奖励信号来优化行为;然而生物大脑是如何实现类似功能的呢?近年来,神经科学与人工智能的交叉研究逐渐揭示了大脑中类似的 奖励预测 机制,多巴胺神经元作为大脑中的 奖励信号器 ,其活动模式与强化学习中的奖励预测误差有着惊人的相似之处。然而,传统的多巴胺神经元模型存在局限性,其只能学习到未来奖励的平均值,而忽略了奖励的时间和数量分布等重要信息,这就好比我们只知道某个地方有宝藏,但不知道宝藏的具体位置和数量;而本文研究通过提出TMRL模型填补了这一空白,从而为我们理解大脑如何处理复杂奖励信息提供了新的思路。
这项研究不仅揭示了多巴胺神经元如何编码未来奖励的时间和数量分布,还展示了这种编码方式如何影响动物的行为;实验中,小鼠的行为(如舔舐行为)与多巴胺神经元活动解码出的奖励时间预测高度相关,这表明大脑确实利用这些信息来指导行为。此外,研究还发现,多巴胺神经元的编码方式能适应环境的变化,当奖励的时间分布发生变化时,神经元的编码参数会相应调整从而更有效地表示新的奖励信息,这种适应性不仅体现了大脑的灵活性,也让我们对如何在复杂多变的环境中做出最优决策有了更深的理解。
综上,这项研究通过揭示多巴胺神经元中的未来奖励多维分布图,为我们理解大脑的决策机制提供了新的视角,其不仅展示了大脑如何利用复杂的奖励信息来指导行为,还揭示了这种编码方式的适应性,这些发现不仅对神经科学领域具有重要意义,也让我们对自己的决策过程有了新的认识。
未来,科学家们将会进一步探索这种多维奖励编码机制在不同物种和不同行为中的作用,以及如何利用这些发现来开发更智能的人工智能系统。总之,这项研究为我们理解大脑的 奖励预测 机制迈出了重要的一步,也为未来的跨学科研究奠定了坚实的基础。(100yiyao.com)
参考文献:
Sousa, M., Bujalski, P., Cruz, B.F.et al..Nature (2025). doi:10.1038/s41586-025-09089-6
版权声明 本网站所有注明“来源:100医药网”或“来源:bioon”的文字、图片和音视频资料,版权均属于100医药网网站所有。非经授权,任何媒体、网站或个人不得转载,否则将追究法律责任。取得书面授权转载时,须注明“来源:100医药网”。其它来源的文章系转载文章,本网所有转载文章系出于传递更多信息之目的,转载内容不代表本站立场。不希望被转载的媒体或个人可与我们联系,我们将立即进行删除处理。 87%用户都在用100医药网APP 随时阅读、评论、分享交流 请扫描二维码下载->